A top-down parser builds the parse tree from the top down, starting with the start non-terminal. There are two types of Top-Down Parsers:
- Top-Down Parser with Backtracking
- Top-Down Parsers without Backtracking
Top-Down Parsers without backtracking can further be divided into two parts:
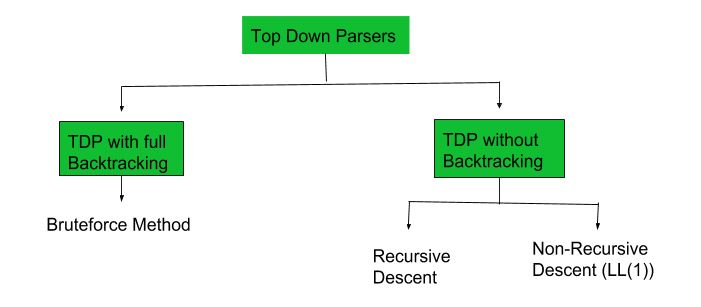
we are going to discuss Non-Recursive Descent which is also known as LL(1) Parser.
LL(1) Parsing:
Here the 1st L represents that the scanning of the Input will be done from Left to Right manner and the second L shows that in this parsing technique we are going to use Left most Derivation Tree. And finally, the 1 represents the number of look-ahead, which means how many symbols are you going to see when you want to make a decision.
Algorithm to construct LL(1) Parsing Table:
Step 1: First check for left recursion in the grammar, if there is left recursion in the grammar remove that and go to step 2.
Step 2: Calculate First() and Follow() for all non-terminals.
- First(): If there is a variable, and from that variable, if we try to drive all the strings then the beginning Terminal Symbol is called the First.
- Follow(): What is the Terminal Symbol which follows a variable in the process of derivation.
Step 3: For each production A –> α. (A tends to alpha)
- Find First(α) and for each terminal in First(α), make entry A –> α in the table.
- If First(α) contains ε (epsilon) as terminal than, find the Follow(A) and for each terminal in Follow(A), make entry A –> α in the table.
- If the First(α) contains ε and Follow(A) contains $ as terminal, then make entry A –> α in the table for the $.
To construct the parsing table, we have two functions:
In the table, rows will contain the Non-Terminals and the column will contain the Terminal Symbols. All the Null Productions of the Grammars will go under the Follow elements and the remaining productions will lie under the elements of the First set.
Now, let’s understand with an example.
Example-1:
Consider the Grammar:
E --> TE'
E' --> +TE' | ε
T --> FT'
T' --> *FT' | ε
F --> id | (E)
*ε denotes epsilonFind their First and Follow sets:
|
Productions |
First |
Follow |
|
|
E
–> TE’ |
{ id, ( } |
{ $, ) } |
|
|
E’
–> +TE’/ε |
{ +, ε } |
{ $, ) } |
|
|
T
–> FT’ |
{ id, ( } |
{ +, $, ) } |
|
|
T’
–> *FT’/ε |
{ *, ε } |
{ +, $, ) } |
|
|
F
–> id/(E) |
{ id, ( } |
{ *, +, $, ) } |
|
Now, the LL(1) Parsing Table is:
|
id |
+ |
* |
( |
) |
$ |
|
|
E |
E –> TE’ |
E –> TE’ |
||||
|
E’ |
E’ –> +TE’ |
E’ –> ε |
E’ –> ε |
|||
|
T |
T –> FT’ |
T –> FT’ |
||||
|
T’ |
T’ –> ε |
T’ –> *FT’ |
T’ –> ε |
T’ –> ε |
||
|
F |
F –> id |
F –> (E) |
As you can see that all the null productions are put under the Follow set of that symbol and all the remaining productions are lie under the First of that symbol.
Note: Every grammar is not feasible for LL(1) Parsing table. It may be possible that one cell may contain more than one production.
Let’s see with an example.
Example-2:
Consider the Grammar
S --> A | a
A --> a Find their First and Follow sets:
|
|
First |
Follow |
|
S
–> A/a |
{ a } |
{ $ } |
|
A
–>a |
{ a } |
{ $ } |
Parsing Table:
|
|
a |
$ |
|
S |
S –> A, S –> a |
|
|
A |
A –> a |
|
Here, we can see that there are two productions into the same cell. Hence, this grammar is not feasible for LL(1) Parser.

















No comments:
Post a Comment