Convolutional Neural Network
Convolutional Neural Network is one of the main categories to do image classification and image recognition in neural networks. Scene labeling, objects detections, and face recognition, etc., are some of the areas where convolutional neural networks are widely used.
Convolutional Neural Networks are a special type of feed-forward artificial neural network in which the connectivity pattern between its neuron is inspired by the visual cortex.
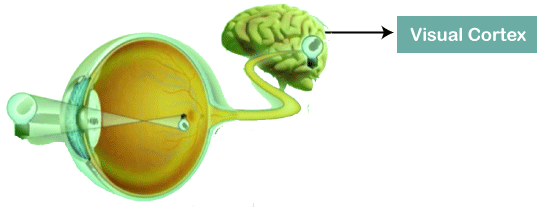
The visual cortex encompasses a small region of cells that are region sensitive to visual fields. In case some certain orientation edges are present then only some individual neuronal cells get fired inside the brain such as some neurons responds as and when they get exposed to the vertical edges, however some responds when they are shown to horizontal or diagonal edges, which is nothing but the motivation behind Convolutional Neural Networks.
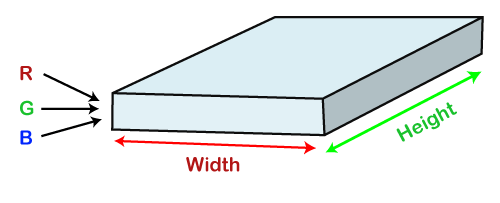
The Convolutional Neural Networks, which are also called as covnets, are nothing but neural networks, sharing their parameters. Suppose that there is an image, which is embodied as a cuboid, such that it encompasses length, width, and height. Here the dimensions of the image are represented by the Red, Green, and Blue channels, as shown in the image given below.
Now assume that we have taken a small patch of the same image, followed by running a small neural network on it, having k number of outputs, which is represented in a vertical manner. Now when we slide our small neural network all over the image, it will result in another image constituting different width, height as well as depth. We will notice that rather than having R, G, B channels, we have come across some more channels that, too, with less width and height, which is actually the concept of Convolution. In case, if we accomplished in having similar patch size as that of the image, then it would have been a regular neural network. We have some wights due to this small patch.
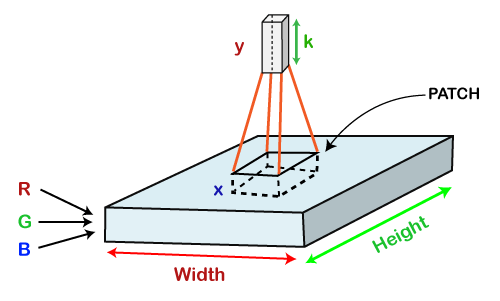
Mathematically it could be understood as follows;
- The Convolutional layers encompass a set of learnable filters, such that each filter embraces small width, height as well as depth as that of the provided input volume (if the image is the input layer then probably it would be 3).
- Suppose that we want to run the convolution over the image that comprises of 34x34x3 dimension, such that the size of a filter can be axax3. Here a can be any of the above 3, 5, 7, etc. It must be small in comparison to the dimension of the image.
- Each filter gets slide all over the input volume during the forward pass. It slides step by step, calling each individual step as a stride that encompasses a value of 2 or 3 or 4 for higher-dimensional images, followed by calculating a dot product in between filter's weights and patch from input volume.
- It will result in 2-Dimensional output for each filter as and when we slide our filters followed by stacking them together so as to achieve an output volume to have a similar depth value as that of the number of filters. And then, the network will learn all the filters.
Working of CNN
Generally, a Convolutional Neural Network has three layers, which are as follows;
- Input: If the image consists of 32 widths, 32 height encompassing three R, G, B channels, then it will hold the raw pixel([32x32x3]) values of an image.
- Convolution: It computes the output of those neurons, which are associated with input's local regions, such that each neuron will calculate a dot product in between weights and a small region to which they are actually linked to in the input volume. For example, if we choose to incorporate 12 filters, then it will result in a volume of [32x32x12].
- ReLU(Rectified Linear Activation Function) Layer: It is specially used to apply an activation function elementwise, like as max (0, x) thresholding at zero. It results in ([32x32x12]), which relates to an unchanged size of the volume.
- Pooling: This layer is used to perform a downsampling operation along the spatial dimensions (width, height) that results in [16x16x12] volume.
- Locally Connected: It can be defined as a regular neural network layer that receives an input from the preceding layer followed by computing the class scores and results in a 1-Dimensional array that has the equal size to that of the number of classes.
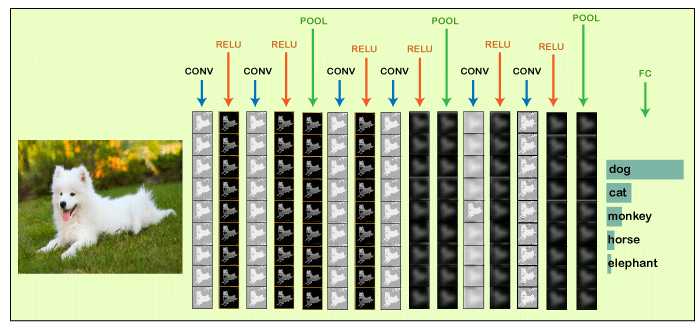
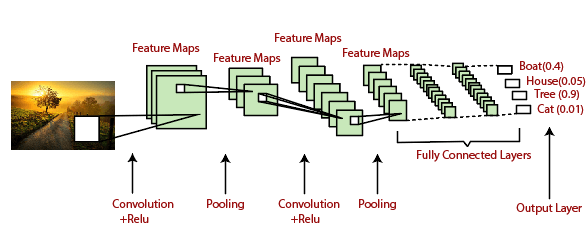
We will start with an input image to which we will be applying multiple feature detectors, which are also called as filters to create the feature maps that comprises of a Convolution layer. Then on the top of that layer, we will be applying the ReLU or Rectified Linear Unit to remove any linearity or increase non-linearity in our images.
Next, we will apply a Pooling layer to our Convolutional layer, so that from every feature map we create a Pooled feature map as the main purpose of the pooling layer is to make sure that we have spatial invariance in our images. It also helps to reduce the size of our images as well as avoid any kind of overfitting of our data. After that, we will flatten all of our pooled images into one long vector or column of all of these values, followed by inputting these values into our artificial neural network. Lastly, we will feed it into the locally connected layer to achieve the final output.
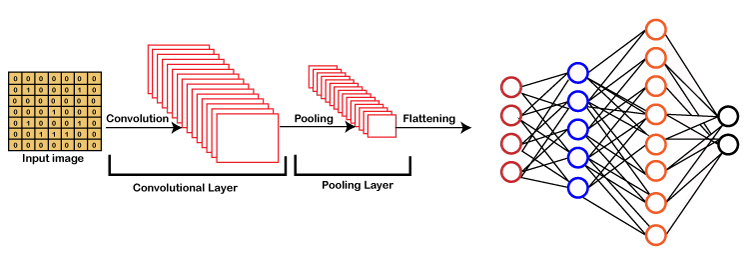
CNN takes an image as input, which is classified and process under a certain category such as dog, cat, lion, tiger, etc. The computer sees an image as an array of pixels and depends on the resolution of the image. Based on image resolution, it will see as h * w * d, where h= height w= width and d= dimension. For example, An RGB image is 6 * 6 * 3 array of the matrix, and the grayscale image is 4 * 4 * 1 array of the matrix.
In CNN, each input image will pass through a sequence of convolution layers along with pooling, fully connected layers, filters (Also known as kernels). After that, we will apply the Soft-max function to classify an object with probabilistic values 0 and 1.
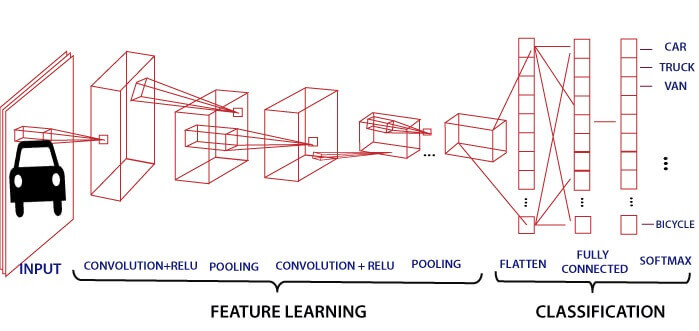
Convolution Layer
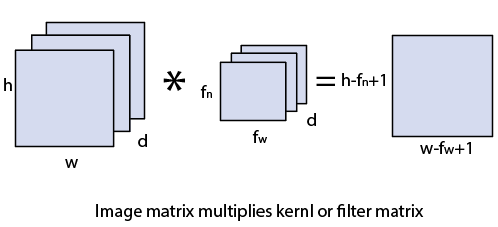
Convolution layer is the first layer to extract features from an input image. By learning image features using a small square of input data, the convolutional layer preserves the relationship between pixels. It is a mathematical operation which takes two inputs such as image matrix and a kernel or filter.
- The dimension of the image matrix is h×w×d.
- The dimension of the filter is fh×fw×d.
- The dimension of the output is (h-fh+1)×(w-fw+1)×1.
Let's start with consideration a 5*5 image whose pixel values are 0, 1, and filter matrix 3*3 as:

The convolution of 5*5 image matrix multiplies with 3*3 filter matrix is called "Features Map" and show as an output.
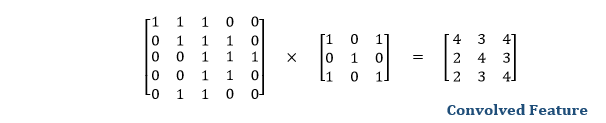
Convolution of an image with different filters can perform an operation such as blur, sharpen, and edge detection by applying filters.
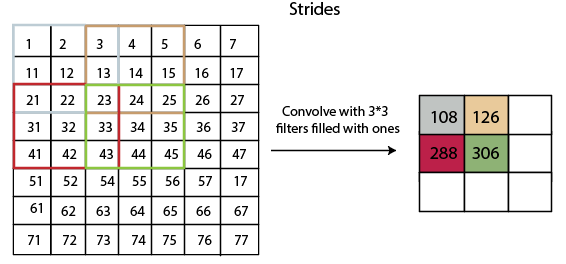
Strides
Stride is the number of pixels which are shift over the input matrix. When the stride is equaled to 1, then we move the filters to 1 pixel at a time and similarly, if the stride is equaled to 2, then we move the filters to 2 pixels at a time. The following figure shows that the convolution would work with a stride of 2.
Padding
Padding plays a crucial role in building the convolutional neural network. If the image will get shrink and if we will take a neural network with 100's of layers on it, it will give us a small image after filtered in the end.
If we take a three by three filter on top of a grayscale image and do the convolving then what will happen?
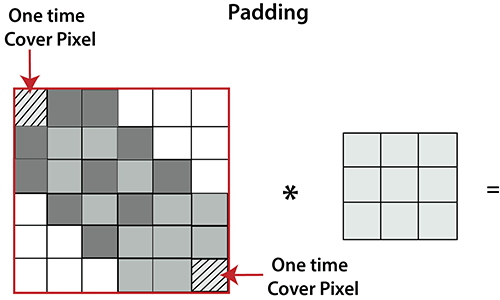
It is clear from the above picture that the pixel in the corner will only get covers one time, but the middle pixel will get covered more than once. It means that we have more information on that middle pixel, so there are two downsides:
- Shrinking outputs
- Losing information on the corner of the image.
To overcome this, we have introduced padding to an image. "Padding is an additional layer which can add to the border of an image."
Pooling Layer
Pooling layer plays an important role in pre-processing of an image. Pooling layer reduces the number of parameters when the images are too large. Pooling is "downscaling" of the image obtained from the previous layers. It can be compared to shrinking an image to reduce its pixel density. Spatial pooling is also called downsampling or subsampling, which reduces the dimensionality of each map but retains the important information. There are the following types of spatial pooling:
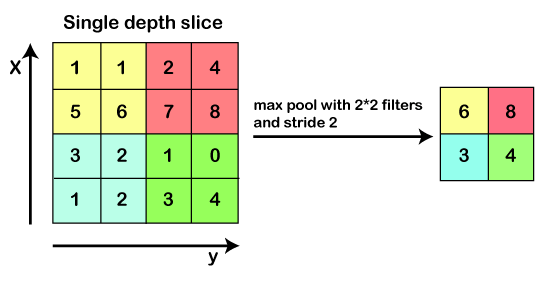
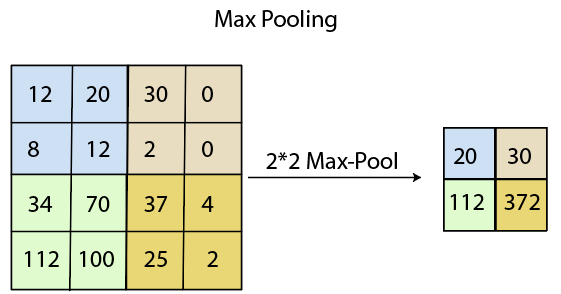
Max Pooling
Max pooling is a sample-based discretization process. Its main objective is to downscale an input representation, reducing its dimensionality and allowing for the assumption to be made about features contained in the sub-region binned.
Max pooling is done by applying a max filter to non-overlapping sub-regions of the initial representation.
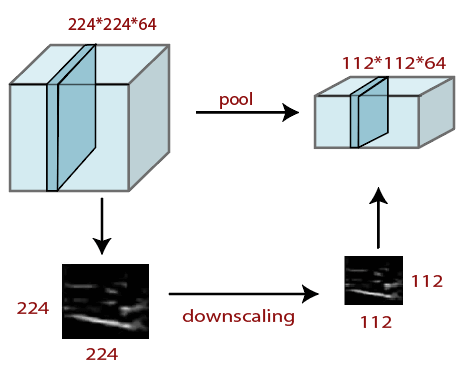
Average Pooling
Down-scaling will perform through average pooling by dividing the input into rectangular pooling regions and computing the average values of each region.
Syntax
layer = averagePooling2dLayer(poolSize) layer = averagePooling2dLayer(poolSize,Name,Value)
Sum Pooling
The sub-region for sum pooling or mean pooling are set exactly the same as for max-pooling but instead of using the max function we use sum or mean.
Fully Connected Layer
The fully connected layer is a layer in which the input from the other layers will be flattened into a vector and sent. It will transform the output into the desired number of classes by the network.
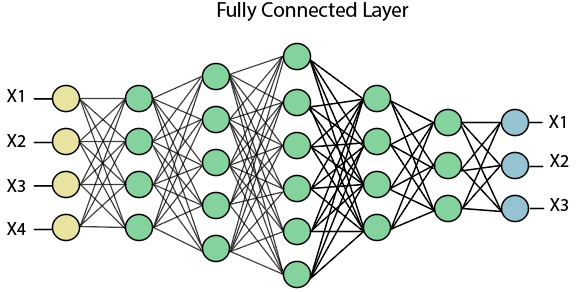
In the above diagram, the feature map matrix will be converted into the vector such as x1, x2, x3... xn with the help of fully connected layers. We will combine features to create a model and apply the activation function such as softmax or sigmoid to classify the outputs as a car, dog, truck, etc.
Ques. Define convolutional network.
Answer
A Convolutional Neural Network (CNN) is a Deep Learning algorithm which can take in
- an input image
- assign importance (learnable weights and biases) to various aspects/objects in the image
- be able to differentiate one from the other.
Convolutional neural networks are very good at picking up on patterns in the input image, such as lines, gradients, circles, or even eyes and faces.It is a feed-forward neural network and contain many convolutional layers stacked on top of each other, each one capable of recognizing more sophisticated shapes.
Ques. Write a short note on the convolutional layer.
Answer
It is a key building block which makes use of a set of learnable filters. A filter is used to detect the presence of specific features or patterns present in the original image (input). A convolution is the simple application of a filter to an input that results in an activation.
Usage:
The usage of convolutional layers in a convolutional neural network mirrors the structure of the human visual cortex, where a series of layers process an incoming image and identify progressively more complex features.
Ques. Describe briefly activation function, pooling and fully connected layer.
Answer
The activation function is a node that is put at the end of or in between Neural Networks. They help to decide if the neuron would fire or not.
Pooling basically reduces the number of parameters and computation in the network, controlling overfitting by progressively reducing the spatial size of the network.
There are 3 types of pooling:
- Max(take out only the maximum from a pool.)
- Min(take out only the minimum from a pool.)
- Average(take out only the average from a pool.)
In Fully Connected Layer the neurons have a complete connection to all the activations from the previous layers.














No comments:
Post a Comment