B Tree
- In a binary search tree, AVL Tree, Red-Black tree etc., every node can have only one value (key) and a maximum of two children but there is another type of search tree called B-Tree in which a node can store more than one value (key) and it can have more than two children.
- B-Tree can be defined as a self-balanced search tree with multiple keys in every node and more than two children for every node. Here, the number of keys in a node and the number of children for a node depend on the order of the B-Tree. Every B-Tree has an order.
B-Tree of Order m has the following properties...
- All the leaf nodes must be at the same level.
- All nodes except the root must have at least ⌈m/2⌉-1 keys and a maximum of m-1 keys.
- All non-leaf nodes except root (i.e. all internal nodes) must have at least ⌈m/2⌉ children.
- If the root node is a non-leaf node, then it must have at least 2 children.
- A non-leaf node with n-1 keys must have n number of children.
- All the key values within a node must be in Ascending Order.
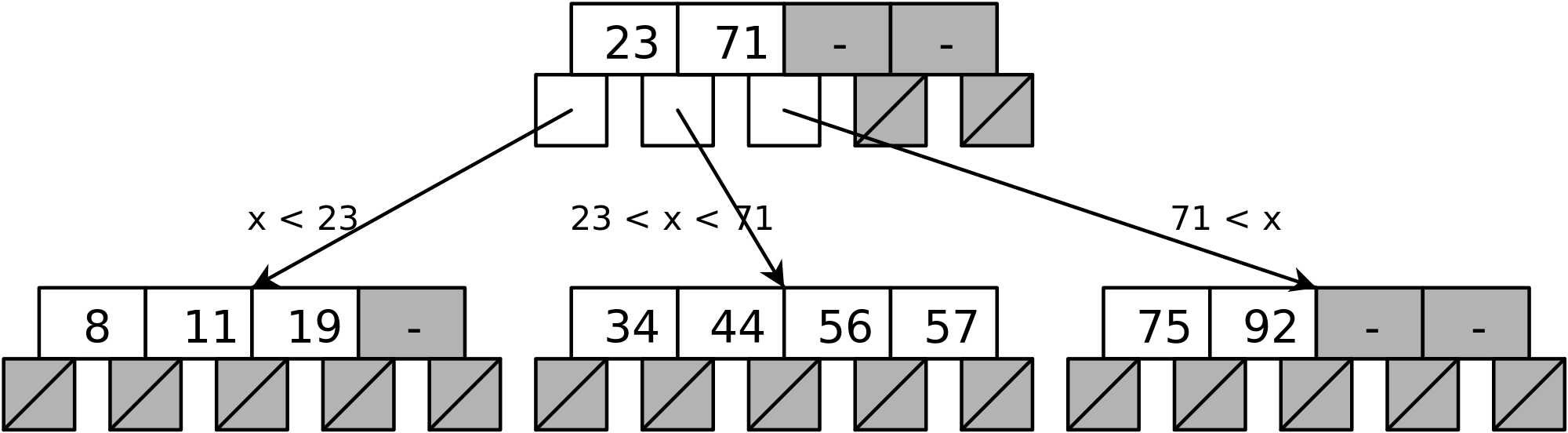
The figure depicts the basic construction of B-Tree.
B-Trees maintain balance by ensuring that each node has a minimum number of keys, so the tree is always balanced. This balance guarantees that the time complexity for operations such as insertion, deletion, and searching is always O(log n), regardless of the initial shape of the tree.
Time Complexity of B-Tree:
| Sr. No. | Algorithm | Time Complexity |
|---|---|---|
| 1. | Search | O(log n) |
| 2. | Insert | O(log n) |
| 3. | Delete | O(log n) |
Note: “n” is the total number of elements in the B-tree
Applications of B-Trees:
- It is used in large databases to access data stored on the disk
- Searching for data in a data set can be achieved in significantly less time using the B-Tree
- With the indexing feature, multilevel indexing can be achieved.
- Most of the servers also use the B-tree approach.
- B-Trees are used in CAD systems to organize and search geometric data.
- B-Trees are also used in other areas such as natural language processing, computer networks, and cryptography.
Advantages of B-Trees:
- B-Trees have a guaranteed time complexity of O(log n) for basic operations like insertion, deletion, and searching, which makes them suitable for large data sets and real-time applications.
- B-Trees are self-balancing.
- High concurrency and high throughput.
- Efficient storage utilization.
Disadvantages of B-Trees:
- B-Trees are based on disk-based data structures and can have a high disk usage.
- Not the best for all cases.
- Slow in comparison to other data structures.
Operations on a B-Tree
The following operations are performed on a B-Tree...
- Search
- Insertion
- Deletion
Search Operation in B-Tree
The search operation in B-Tree is similar to the search operation in Binary Search Tree. In a Binary search tree, the search process starts from the root node and we make a 2-way decision every time (we go to either the left subtree or the right subtree). In B-Tree also search process starts from the root node but here we make an n-way decision every time. Where 'n' is the total number of children the node has. In a B-Tree, the search operation is performed with O(log n) time complexity. The search operation is performed as follows...
- Step 1 - Read the search element from the user.
- Step 2 - Compare the search element with the first key value of the root node in the tree.
- Step 3 - If both are matched, then display "Given node is found!!!" and terminate the function
- Step 4 - If both are not matched, then check whether the search element is smaller or larger than that key value.
- Step 5 - If the search element is smaller, then continue the search process in the left subtree.
- Step 6 - If the search element is larger, then compare the search element with the next key value in the same node and repeated steps 3, 4, 5, and 6 until we find the exact match or until the search element is compared with the last key value in the leaf node.
- Step 7 - If the last key value in the leaf node is also not matched then display "Element is not found" and terminate the function.
Insertion Operation in B-Tree
In a B-Tree, a new element must be added only at the leaf node. That means the new keyValue is always attached to the leaf node only. The insertion operation is performed as follows...
- Step 1 - Check whether the tree is Empty.
- Step 2 - If the tree is Empty, then create a new node with a new key value and insert it into the tree as a root node.
- Step 3 - If the tree is Not Empty, then find the suitable leaf node to which the new key value is added using Binary Search Tree logic.
- Step 4 - If that leaf node has an empty position, add the new key value to that leaf node in ascending order of key value within the node.
- Step 5 - If that leaf node is already full, split that leaf node by sending the middle(median) value to its parent node. Repeat the same until the sending value is fixed into a node.
- Step 6 - If the splitting is performed at the root node then the middle value becomes new root node for the tree and the height of the tree is increased by one.
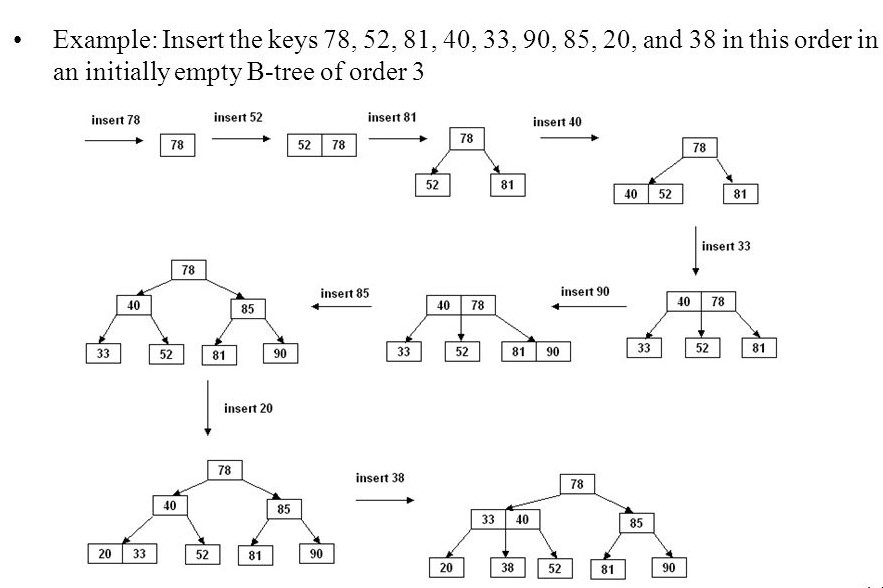
The figure illustrates the steps of insertion of an element in a B-Tree.
Deletion Operation in B-Tree
While inserting a key, we had to ensure that the number of keys should not exceed MAX. Similarly, while deleting, we must watch that the number of keys in a node should not become less than MIN. While inserting, when the keys exceed MAX, we split the node into two nodes, and the median key went to the parent node; while deleting when the keys will become less than MIN, we will combine two nodes into one.
At the leaf nodes, deletion is also conducted. It can be a leaf node or an inside node that must be destroyed. To delete a node from a B tree, use the following algorithm.
- Find the position of the leaf node.
- If the leaf node has more than the minimum keys, delete the required key from the node.
- If the leaf node lacks minimum keys, fill in the gaps with the eighth or left sibling element.
- If the left sibling has more than the minimum elements, shift the intervening element down to the node where the key is deleted and push the largest element up to its parent.
- If the right sibling has more than the minimum items, shift the intervening element down to the node where the key is deleted and push the smallest element up to the parent.
- Create a new leaf node by merging two leaf nodes and the parent node's intervening element if neither sibling has more than the minimum elements.
- If the parent has less than the minimum nodes, repeat the operation on the parent as well.
If the node to be destroyed is an internal node, its in-order successor or predecessor should be used instead. Because the successor or predecessor will always be on the leaf node, the operation will be similar to deleting the node from the leaf node.
Explanation Points:
Now let us see how all this is done by studying the deletion cases. Deletion in a B-Tree can be classified into two cases:
- Deletion from the leaf node.
- Deletion from the non-leaf node.
1. Deletion From Leaf Node.
It will be divided into various cases. Let us study every case in detail.
If Node Has More Than MIN Keys,
In this case, deletion is very straightforward, and the key can be very easily deleted from the node by shifting other keys of the node.
If Node Has MIN Keys
After the deletion of a key, the node will have less than MIN keys and will become an underflow node. In such a case, we can borrow a key from the left or right sibling if any one of them has more than the MIN keys.
Now you must be wondering which sibling to start from?
In our algorithm, we'll first try to borrow a key from the left sibling; if the left sibling has only MIN keys, then we'll try to borrow from the right sibling.
- When a key is borrowed from the left sibling, the separator key in the parent is moved to the underflow node, and the last key from the left sibling is moved to the parent.
- When a key is borrowed from the right sibling, the separator key in the parent is moved to the underflow node, and the first key from the right sibling is moved to the parent. All the remaining keys in the right sibling are moved from one position to the left.
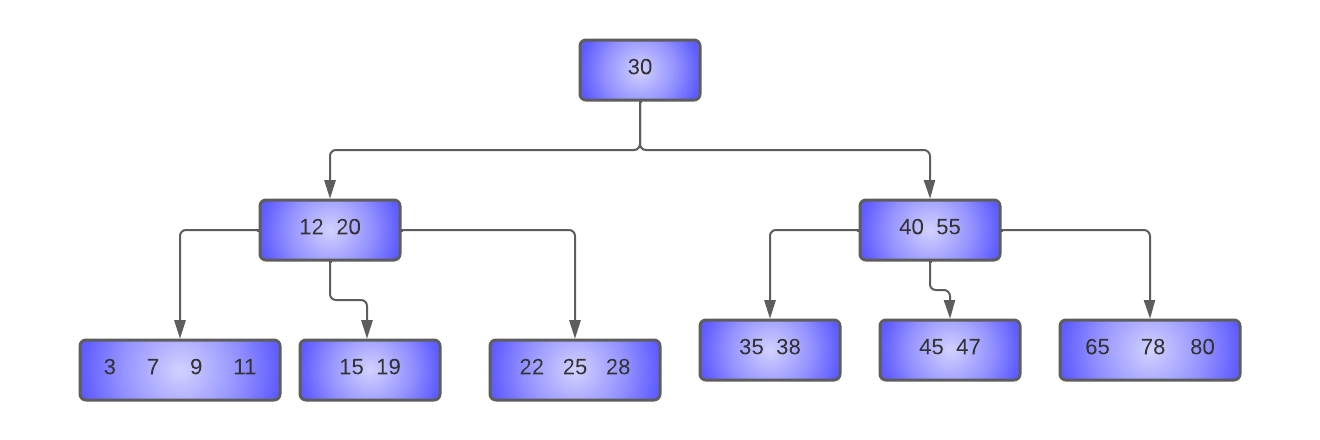
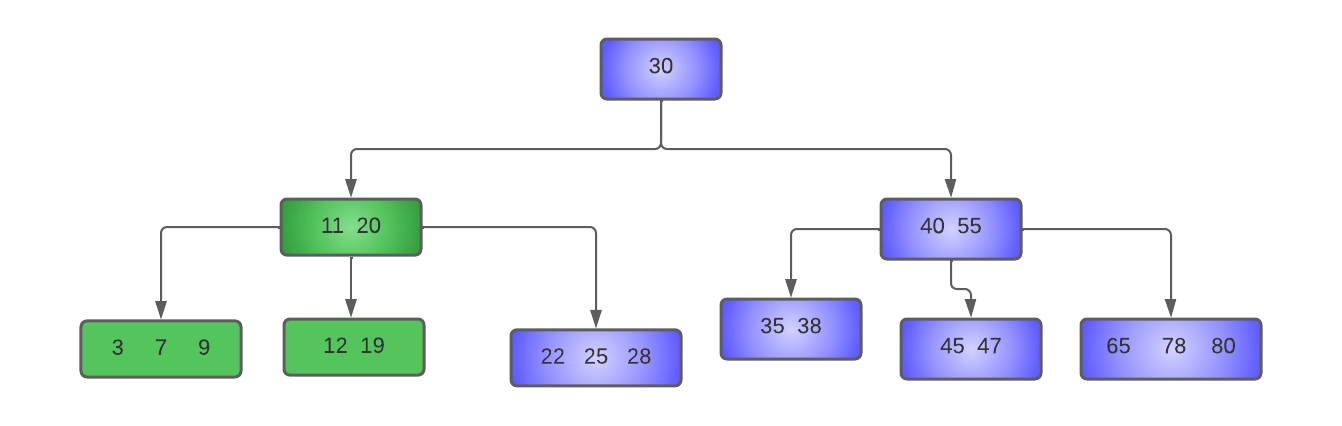
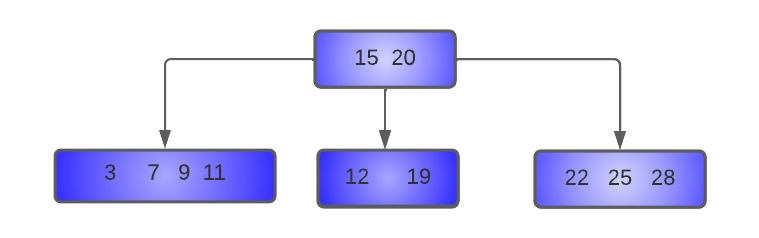
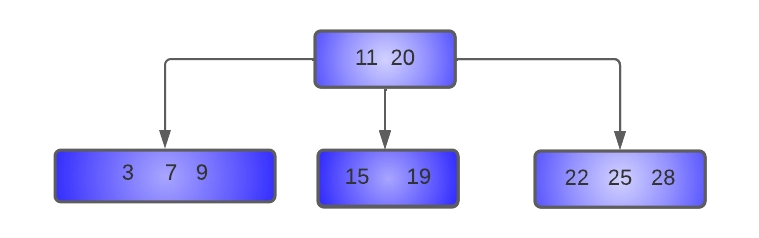
- Delete 15 from the tree:
Here key 15 is to be deleted from the node [15, 19]. Since this node has only MIN keys, we will try to borrow from its left sibling[ 3,7,9,11], which has more than MIN keys.
The parent of these nodes is node [12, 20], and the separator key is 12. Hence, the last key of the left sibling (11) is moved to the place of the separator key, which is moved to the underflow node.
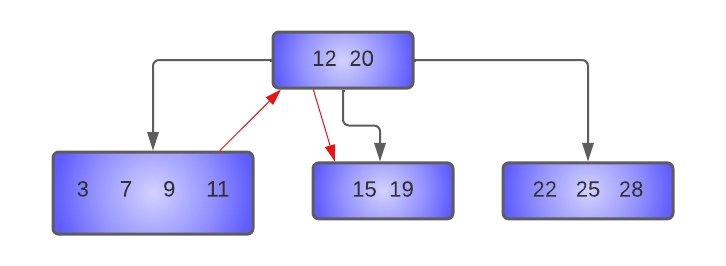
The resulting tree after deletion of 15 will be:-
Note: The involvement of the separator key is necessary since if we simply borrow 11 and put it at the place of 15, then the property of the B-tree will be violated.
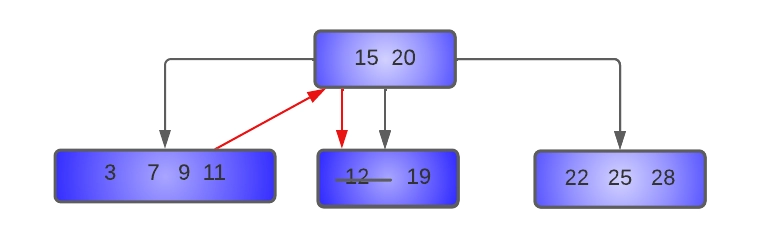
- Delete 19 from the tree:
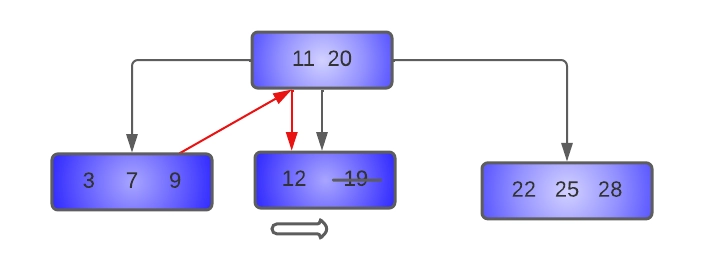
As we can see above, key 19 will be deleted by borrowing the left sibling, so key nine will be moved up to the parent node, and 11 will be shifted to the underflow node. In the underflow node, the key 12 will be shifted to the right to make place for 11. The resultant tree will look like this:
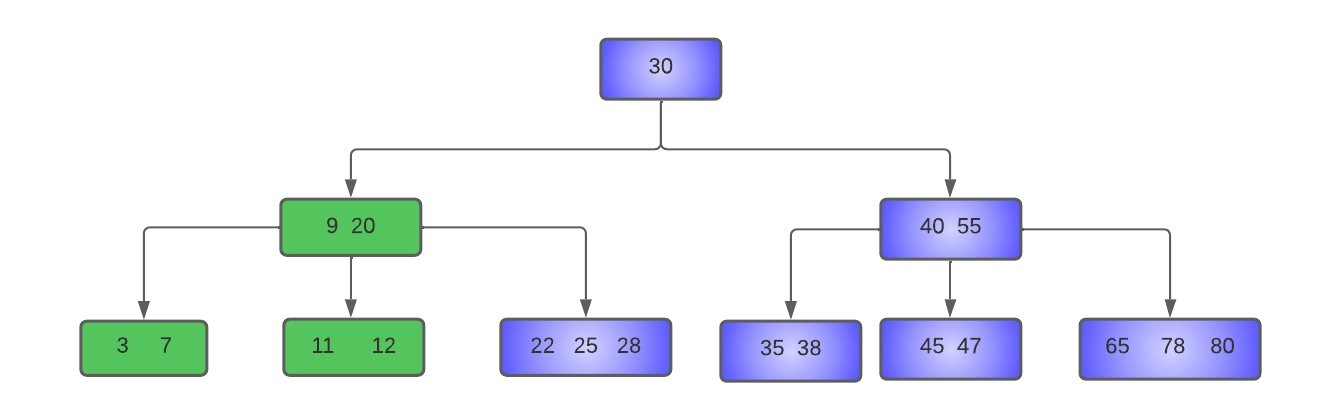
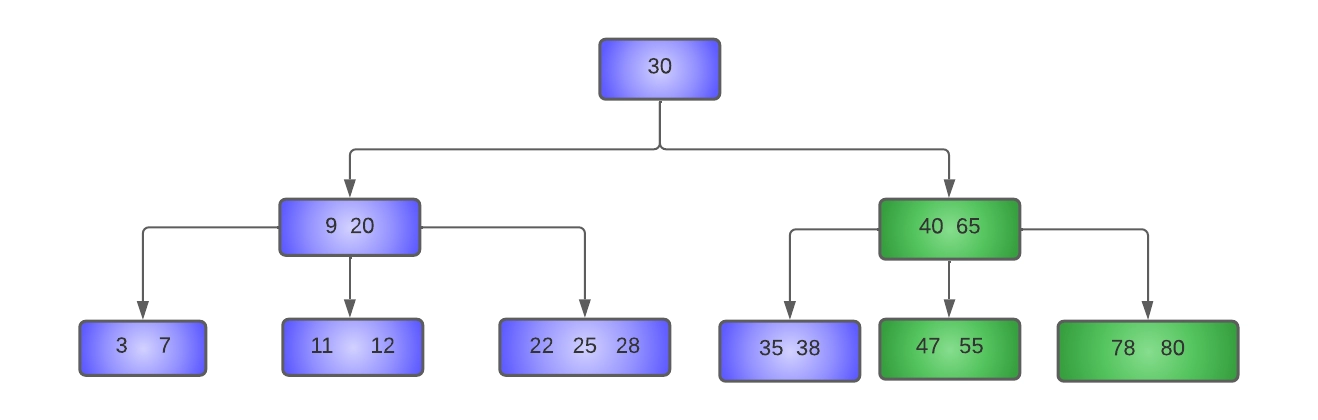
- Delete 45 from the tree:
As we can see in the diagram itself, the left sibling of the [45, 47] is [35, 38], which has only MIN keys, so we can't borrow from it. Thus, we will try to borrow from the right sibling, i.e., [65, 78, 80]. As discussed above, while borrowing from the right sibling, the first key of the node is moved to the parent node. In this case, the first key of the right sibling(65) will be moved to the parent node, and the separator key from the parent node(55) will be moved to the underflow node.
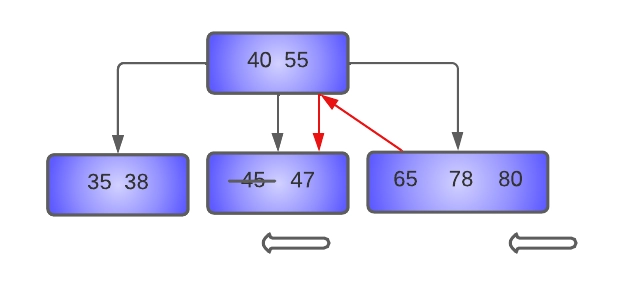
In the underflow node, 47 is shifted left to make room for 55. In the right sibling, 78 and 80 are moved to the left to fill the gap created by the removal of 65.
The resulting tree will look like this:
Note: If both left and right siblings of the underflow node have MIN keys, then we can’t borrow from any of the siblings. In this case, the underflow node is combined with its left( or right ) sibling.
Let’s see an example for the same:
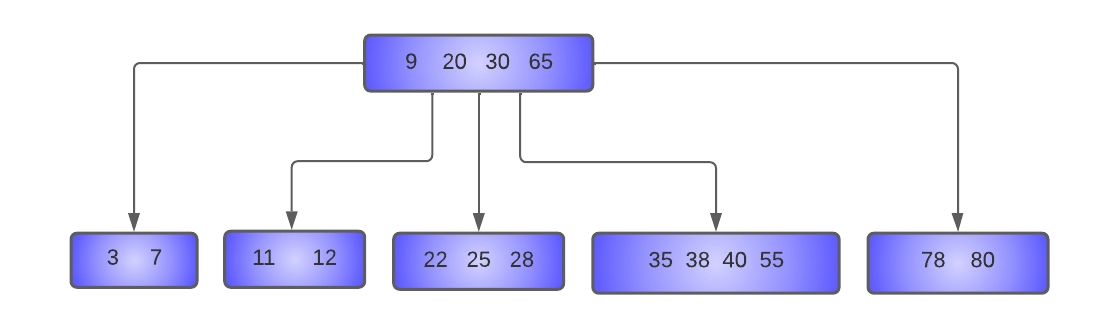
- Delete 47 from the tree:
If we try to delete 47 from the tree which has only MIN keys and if we delete it, it leads to the underflow condition, so we'll try to borrow from the left sibling [ 35, 38], which also has only MIN keys, then we try to borrow from the right sibling [ 78, 80] which has again MIN keys only. So, what should we do now?
We’ll combine the left sibling node with the key left in the current node. For combining these two nodes, the separator key(40) from the parent node will move down in the combined node.
But the parent node also has only MIN keys.
In this case, when the parent node becomes underflow, we will borrow a key from its left sibling. But if we look at its left sibling, it also has only MIN keys.
Here, the separator key ( 30) the root node comes down in the combined node, which becomes the new root of the tree, and the height of the tree decreases by one.
The resulting tree will look like this:
Deletion From Non-Leaf Node,
In this case, the successor key is copied at the place of the key to be removed, and then the successor is deleted. The successor key is the smallest key in the right subtree and will always be in the leaf node. So this case reduces to the above-mentioned approaches.
Let’s retake the above B-tree example:
- Delete 12 from the tree:
The successor key of 12 is 15, this we’ll copy 15 at the place of 12, and now our task reduces to the deletion of 15 from the leaf node. This deletion is performed by borrowing a key from the left sibling.
Example:
Here, we show the letter-by-letter deletion of the letters A L G O R I T H M S from the tree that is formed after inserting them.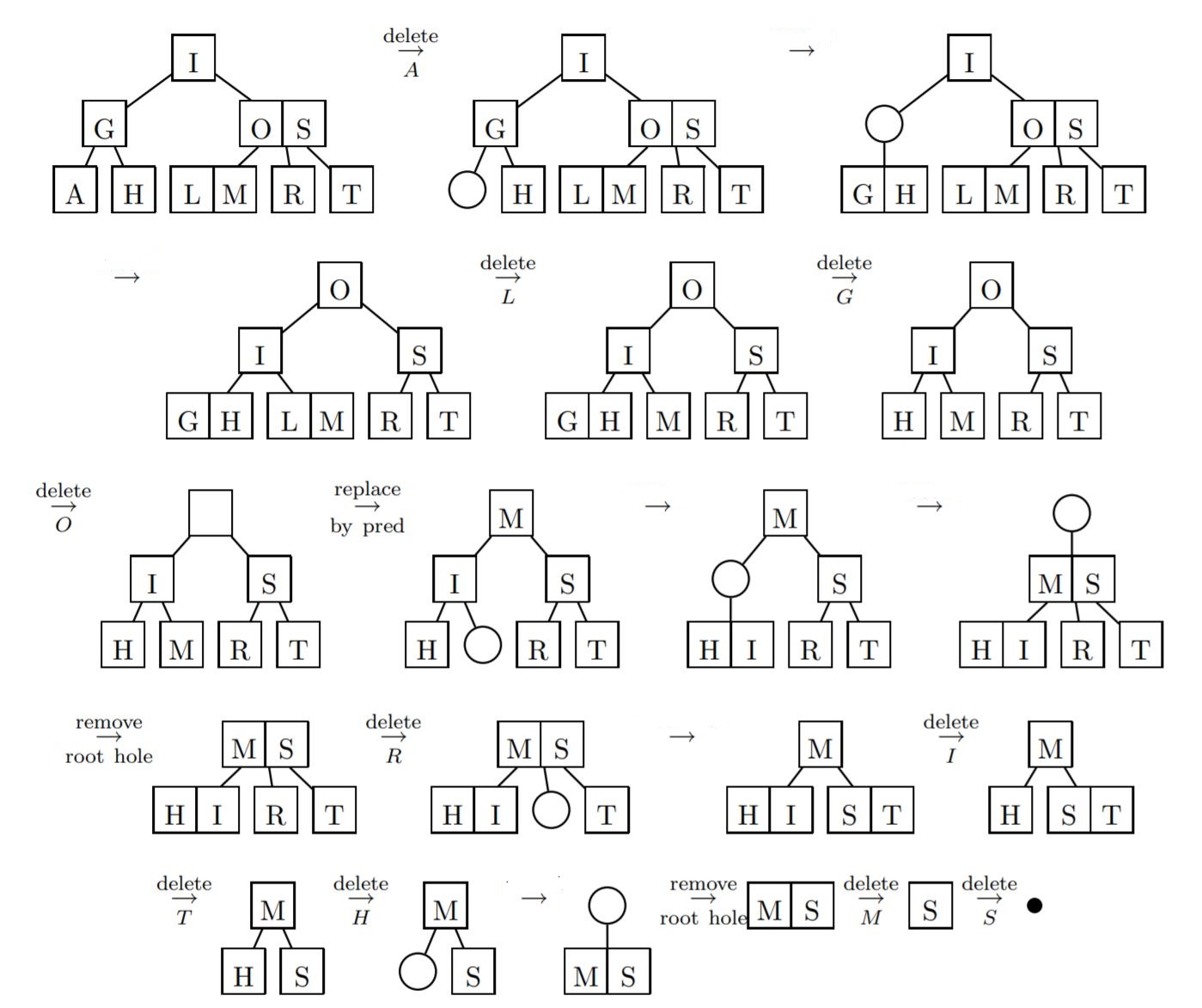
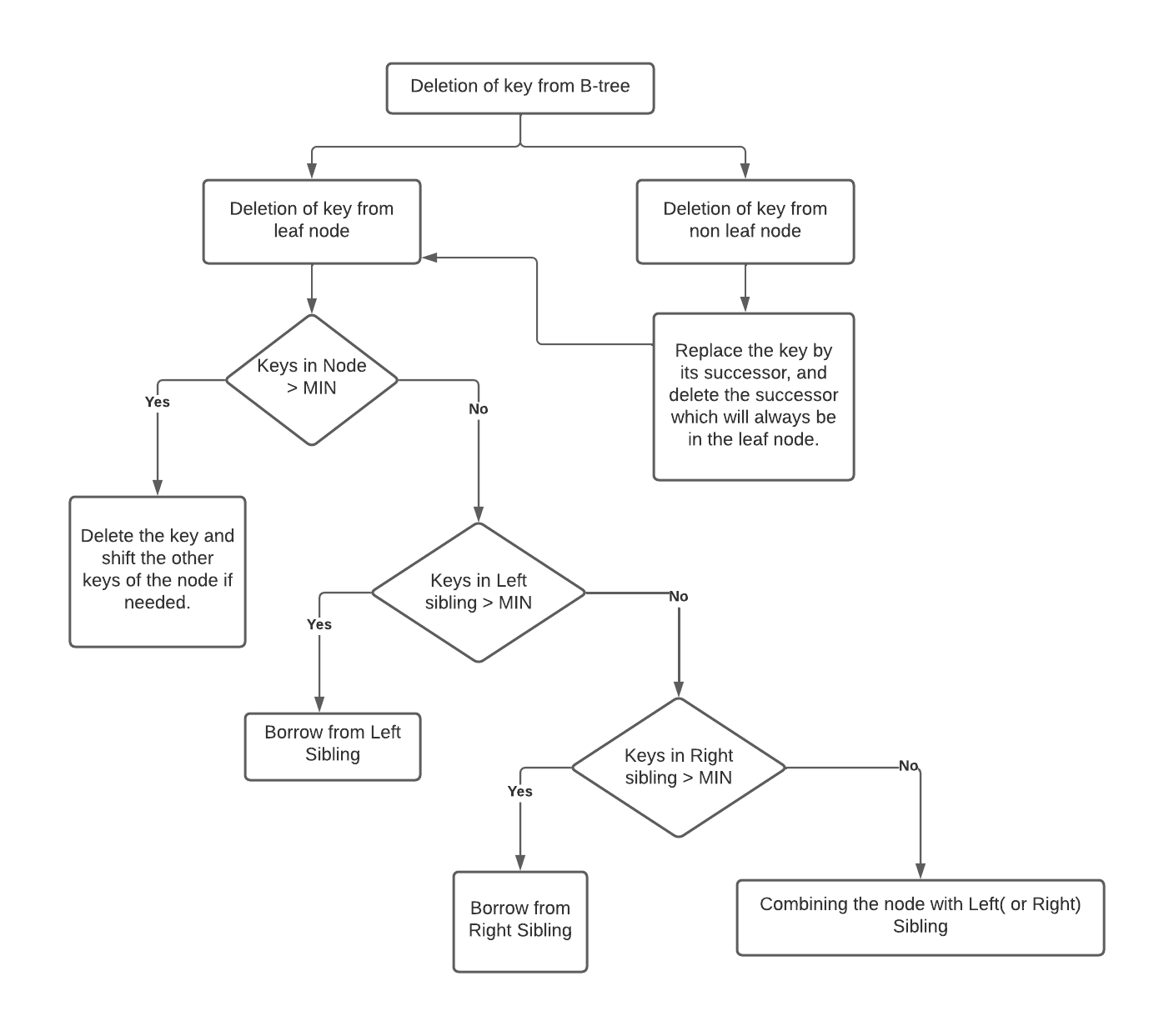
Now let us conclude the above discussion by looking at the flowchart:
















No comments:
Post a Comment