Reinforcement Learning Algorithms
Reinforcement learning algorithms are mainly used in AI applications and gaming applications. The main used algorithms are:
- Q-Learning:
- Q-learning is an Off policy RL algorithm, which is used for the temporal difference Learning. The temporal difference learning methods are the way of comparing temporally successive predictions.
- It learns the value function Q (S, a), which means how good to take action "a" at a particular state "s."
- The below flowchart explains the working of Q- learning:
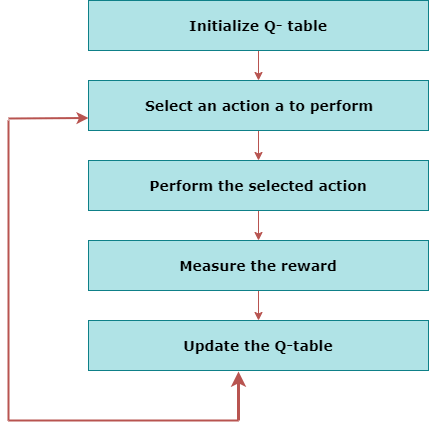
- State Action Reward State action (SARSA):
- SARSA stands for State Action Reward State action, which is an on-policy temporal difference learning method. The on-policy control method selects the action for each state while learning using a specific policy.
- The goal of SARSA is to calculate the Q π (s, a) for the selected current policy π and all pairs of (s-a).
- The main difference between Q-learning and SARSA algorithms is that unlike Q-learning, the maximum reward for the next state is not required for updating the Q-value in the table.
- In SARSA, new action and reward are selected using the same policy, which has determined the original action.
- The SARSA is named because it uses the quintuple Q(s, a, r, s', a'). Where,
s: original state
a: Original action
r: reward observed while following the states
s' and a': New state, action pair.
- Deep Q Neural Network (DQN):
- As the name suggests, DQN is a Q-learning using Neural networks.
- For a big state space environment, it will be a challenging and complex task to define and update a Q-table.
- To solve such an issue, we can use a DQN algorithm. Where, instead of defining a Q-table, neural network approximates the Q-values for each action and state.
Now, we will expand the Q-learning.
Q-Learning Explanation:
- Q-learning is a popular model-free reinforcement learning algorithm based on the Bellman equation.
- The main objective of Q-learning is to learn the policy which can inform the agent that what actions should be taken for maximizing the reward under what circumstances.
- It is an off-policy RL that attempts to find the best action to take at a current state.
- The goal of the agent in Q-learning is to maximize the value of Q.
- The value of Q-learning can be derived from the Bellman equation. Consider the Bellman equation given below:
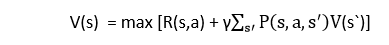
In the equation, we have various components, including reward, discount factor (γ), probability, and end states s'. But there is no any Q-value is given so first consider the below image:

In the above image, we can see there is an agent who has three values options, V(s1), V(s2), V(s3). As this is MDP, so agent only cares for the current state and the future state. The agent can go to any direction (Up, Left, or Right), so he needs to decide where to go for the optimal path. Here agent will take a move as per probability bases and changes the state. But if we want some exact moves, so for this, we need to make some changes in terms of Q-value. Consider the below image:
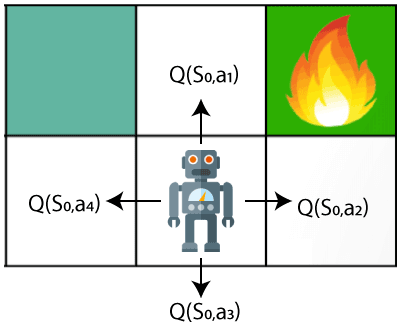
Q- represents the quality of the actions at each state. So instead of using a value at each state, we will use a pair of state and action, i.e., Q(s, a). Q-value specifies that which action is more lubricative than others, and according to the best Q-value, the agent takes his next move. The Bellman equation can be used for deriving the Q-value.
To perform any action, the agent will get a reward R(s, a), and also he will end up on a certain state, so the Q -value equation will be:
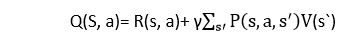
Hence, we can say that, V(s) = max [Q(s, a)]
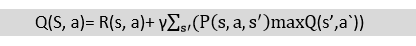
The above formula is used to estimate the Q-values in Q-Learning.
What is 'Q' in Q-learning?
The Q stands for quality in Q-learning, which means it specifies the quality of an action taken by the agent.
Q-table:
A Q-table or matrix is created while performing the Q-learning. The table follows the state and action pair, i.e., [s, a], and initializes the values to zero. After each action, the table is updated, and the q-values are stored within the table.
The RL agent uses this Q-table as a reference table to select the best action based on the q-values.
















No comments:
Post a Comment